一 协作型过滤

二 搜集偏好
使用嵌套的字典表示偏好:

对于规模巨大的数据集而言,使用数据库来存储信息
无论用什么方式来表达偏好,最重要的是,将偏好对应到数字。如:表达人们是否购买过商品,0表示没有买过,1表示买过;对于一个新闻故事的投票网站,-1表示不喜欢,0表示没有投票,1表示喜欢。
三 寻找相近用户
用于确定人们品味方面的相似程度,相似度评价体系(只介绍2种):
1. 欧几里得距离评价
公式: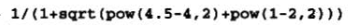
函数pow(n,2)用于求平方。上式为点(4.5,1)与点(4,2)之间的距离的倒数。
由于两个人在偏好空间中的距离越近,其兴趣偏好越相似,数值越小。为了对偏好越相似的情况给出越大的值,将函数值加1(避免被0整除),并取其倒数。
2. 皮尔逊相关度评价

优势:···在数据不是很规范(normalized)的时候(比如影评者对影片的评价总是相对于平均水平偏离很大时),会倾向于给出更好的结果。
···可以修正“夸大分值”的情况,如:两个评论者对不同的电影的评分情况如下图
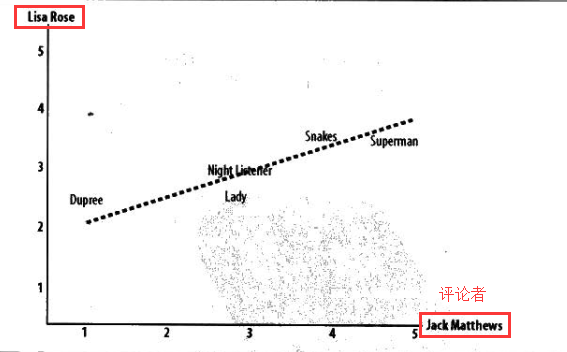

算法流程:首先找到两位评论者都曾评价过的物品,然后计算两者的评分总和与平方和,并求得两者的评分的乘积之和。代码如下:


其他的度量方法:
四 为评论者打分
使用相似度量寻找最接近的n个结果(排序)

五 推荐物品